
We have been re-doing our site back in September 2016. As part of that process, we also deleted a bunch of pages. One month later, Google Search Console is showing a significant increase in crawl errors. Today’s article will show why this happened, how to determine if this is a potential SEO problem for us and how to easily fix URL crawl errors for your own site, using Search Console Helper.
Website overhaul
Back in September 2016, our website badly needed an upgrade. So, we went ahead and completely overhauled it. We changed the design. We changed the navigation structure. And, we also removed a number of unwanted pages.
Most of the pages removed were older blog posts. The reason we removed them was because the content wasn’t not ours. Although thematically relevant, each post was basically an excerpt lifted from another source with a link to the original article. None of the pages contained any original text, whatsoever.
Whether it was a good idea to remove the unoriginal blog posts is for another discussion. At that time, however, we felt that it was the right thing to do. So, we just trashed the posts in the WordPress backend.
New crawl errors
Fast-forward one month later and this is what we see in our Google Search Console’s Crawl Error report:
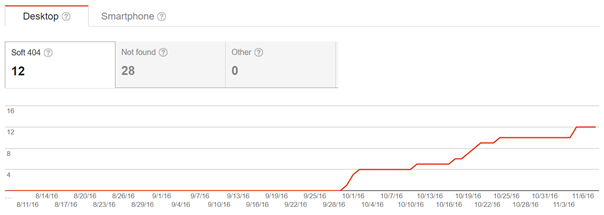
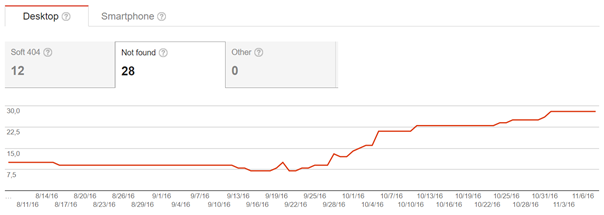
These screenshots clearly show that something happened in the second half of September. It didn’t take too much analysis to realize that the reason is our own website re-design project.
How problematic are URL crawl errors?
The short answer is, it depends.
First of all, to see a large number of crawl errors is actually not that rare. If it’s your case, don’t freak out (just yet).
The reasons for crawl errors can be numerous. Not all of them are necessarily an issue and some you only have a limited control over as a webmaster. Also, not all of them require action.
However, when you see a sudden or steady increase in URL crawl errors, you need to investigate.
When deciding on when to act, the most important thing to remember is that Google always shows you the most serious errors at the top of the list. Therefore, always start your analysis at the top and work your way down. Once you get to the first non-issue, you can pretty much mark all the rest as fixed.
So, let’s a look at our errors in order to determine if they are a problem or not.
Here is where I open my Search Console Helper (our own tool), to which we just added the crawl error feature. I just want to test it out and allow you to see first-hand what it does.
Right away, I can see two types of errors and the same numbers as Google shows (it’s because Search Console Helper gets data directly from Google):
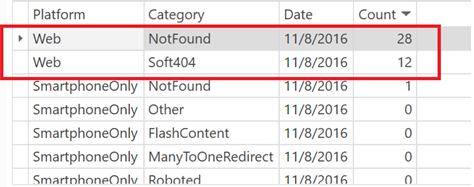
Soft 404 Errors
7 URLs on the list do not return a 404 response code, yet Google judges them as “Not Found”. These are called “soft 404 errors”. Without going into unnecessary technical details, soft 404’s happen when a page behaves like it exists, when it actually doesn’t.
A typical example of this on a WordPress site, would an archive page, such as category or tag, with no posts.
As you can see from the URL structure below, all our soft 404’s are tag archive pages.
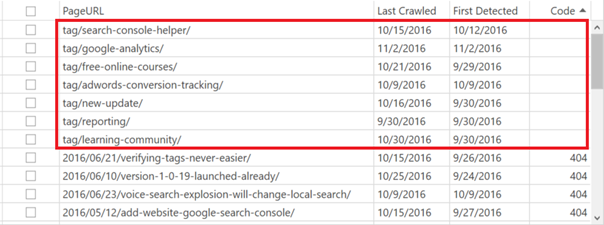
These soft 404’s are a problem that need to be dealt with. As Google explains:
Returning a code other than 404 (Not Found) or 410 (Gone) for a non-existent page, or redirecting users to another page, such as the homepage, instead of returning a 404, can be problematic. Firstly, it tells search engines that there’s a real page at that URL. As a result, that URL may be crawled and its content indexed. Because of the time Googlebot spends on non-existent pages, your unique URLs may not be discovered as quickly or visited as frequently and your site’s crawl coverage may be impacted.
By the way, there is one other instance when Google might interpret pages as soft 404’s. This is when you are redirecting a large amounts of pages to the home page, even when you are using true 301 redirects.
As a best practice, Google recommends that you always return a 404 (Not found) or a 410 (Gone) response code in response to a request for a non-existing page. If you stick to that advice, you should be fine.
404 Not Found Errors
The rest of our crawl errors are marked as 404 Not Found.
Despite their reputation, 404’s are nothing to fear or obsess about. When a page stops existing, it is completely normal that they return a 404 response code.
The only exception is when the page stopped existing because it was replaced by another page. In that case, the old page should redirect to the new one with a 301 Moved Permanently redirect.
However, you still need to keep very close attention to your 404 crawl errors, because you don’t want any of your “money pages” to end up on that list. If that happens, you need to deal with it as soon as possible.
Let’s now look at how we fixed our errors…
How to fix URL crawl errors?
The general set of rules for deciding on how to fix URL crawl errors is the following:
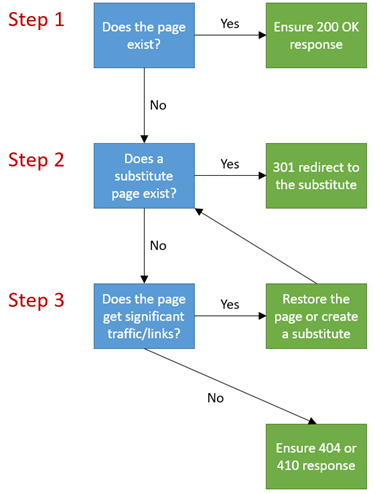
- Does the page exist? If yes, ensure the server header response is 200 OK. If no, proceed to the next question.
- Does a substitute (similar/relevant/related) page exist? If yes, 301-redirect the non-existing URL to the substitute page. If no, proceed to the next question
- Does the page receive significant traffic or links? If yes, recreate the page on the same URL and ensure that the server header response code is 200 OK. Or, create a relevant/related page and 301-redirect the non-existing URL to it. If no, ensure the server header response is 404 Not Found or 410 Gone.
With that in mind, let’s now get to fixing our errors.
Fixing Soft 404 errors
As already noted, all our soft 404 errors are tag archive pages. The reason they show “Not Found” is because no posts are tagged with those tags, any longer (since the posts were deleted).
So, the answer to question 1 above (“Does the page exist?”) is a No for all soft 404 errors.
The answer to the question 2 (“Does a similar/relevant/related page exist?”) is also a no, since we are no longer using those tags anywhere on the site.
That leaves us with only one remaining question, number 3 (“Does the page receive any significant traffic or links?”).
Double-clicking each URL in Search Console Helper, get a window that tells me when the error was first time detected, when the page was last time crawled and, most importantly, also a list of URLs that Google found linking to our non-existing page:
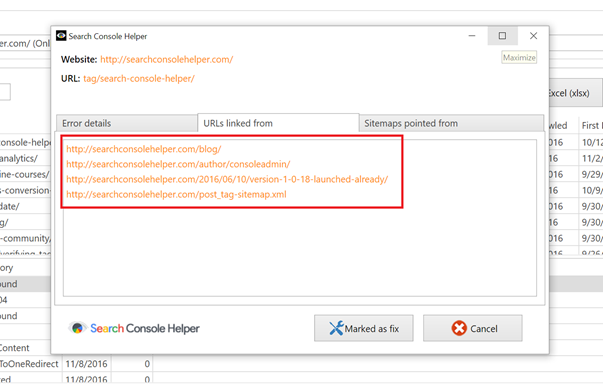
Going through the list, I see that all of the linking URLs are internal and, in fact, either no longer exist themselves or no longer link to the URL in question.
Therefore, I can safely conclude that the page is not receiving any significant links.
I’m not going to check the traffic, because this is a non-essential page. And, also because, I know that the tag archives are not getting any significant traffic, anyway.
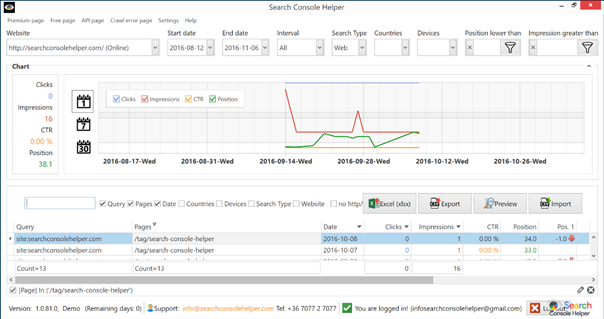
However, if I wanted to check the traffic, I could easily look that page up in Search Console Helper and find that the only time this page received any impressions (not even traffic) was when somebody did a site:searchconsolehelper.com search in Google:
Now that I know that the tag archive can be safely removed, I can log into my WordPress backend and delete the tag.

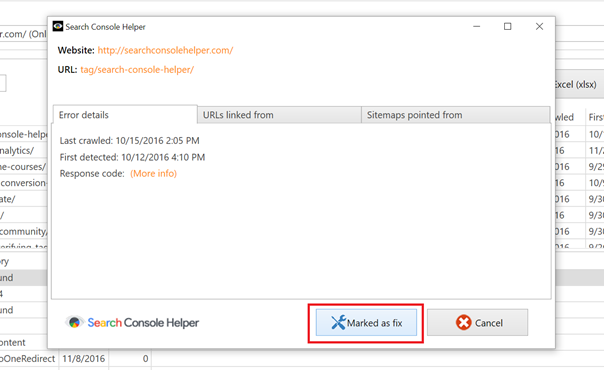
The only thing that remains to be done, is to notify Google that this issue has been resolved. I do that by clicking the “Mark as fixed” button and let Search Console Helper take care of the rest.
In fact, I know I can delete and mark as fixed all my other soft 404 crawl errors, because all of them are tag archive URLs, which are no longer used for anything.
So, I simply check all the rows in Search Console Helper and click the Mark as fixed button on top:

Fixing 404 Not Found Errors
Fixing these crawl errors should follow the same general set of rules as noted above.
Because I know that we have deleted a bunch of unoriginal posts and there are no substitute pages for any of them, I can go ahead, check all of them in Search Console Helper and hit Mark as fixed. This basically tells Google that it’s OK to show them as 404 Not Found and there is no longer a need to crawl them.
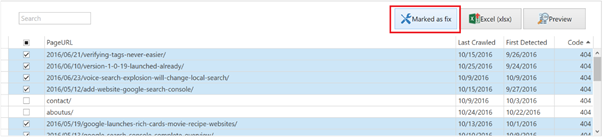
Doing this left me with 5 URLs, which I’m not 100% should return the 404 Not Found response code.
First, there is the “contact” page, which I know should work. And, sure enough, when I click the page URL from Search Console Helper, the page comes up just fine.
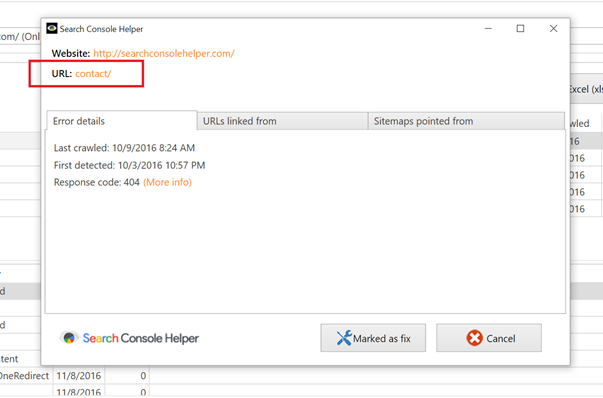
While I don’t know what caused the page to be not found, I know that the page is working fine and I can mark both “contact” URLs as fixed.

The 3 remaining pages are all URLs that we no longer use, but for which there exist substitute pages. All that I need to do, is properly redirect them to their respective “new home” and mark them as fixed in Search Console Helper.
Conclusion
So, there you have it: a simple way to take care of your URL crawl errors.
You should do this at least once per week. More often, if you are just moving your site to another server, changing URL structure, doing a lot of redirects, etc.
While you can do most of this through Google Search Console, Search Console Helper is easier (and faster) to use. Make sure you give it a try!